Authors:
Abdur Rehman – MSDS19002
Fizza Tauqeer – MSDS19034
Aqsa Khalid – MSDS19046
Revisiting Linear Regression in 2D space:
Given a point in (x, y), the Least Squares Error objective function is a continuous function defined as:


This equation can, however, also be written as:
where


The above equation has been made homogeneous to allow a linear process to take place, all the while adding bias ‘1’ into the weights represented by 
Our aim with Linear Regression is to find such a line fit that covers the majority of many such exemplary points as definitively as possible, keeping the error zero or as minimum as can be.
The ‘Need’ for Logistic Regression:
A linear classifier makes a classification decision for a given observation based on the value of a linear combination of the observation’s features – basically the task of which element has what label.
In a ‘binary’ linear classifier, the observation is classified into one of two possible classes using a linear boundary in the input feature space as shown below.

Suppose we have a binary classifier, namely in the form:


where each matrix value depicts a unique class. Given any 
Logically, yes. However, it becomes increasingly messy for an otherwise simple problem. Two issues that we clearly run into when applying Linear Regression are:
- The predicted value is not probabilistic – rather it is continuous (something that we are not interested in with respect to the binary classification problem).
- The model becomes sensitive to imbalanced data.
Defining a discrete function,
which defines points present on one side of the boundary line as ‘1’ and on the other side as ‘-1,’ where each is class. We will attempt to compute this classification’s Error function.

Machine Learning Applicability:
While trying to solve a problem through Machine Learning, it is rudimentary yet pivotal to understand foremost whether ML can even be applied on it. This can be gathered from the following requirements:
- Existence of patterns.
- One cannot write a parameterized function to define it – the model must be able to do that by itself.
There are numerous functions that are able enough for such a task, but the goal is to utilize the smallest parameter function that can linearly model our problem. Finding out this function was assigned as an exercise by the professor.
Consider the Error function below:
![E(x_i) = [f(x_i)-l_i]^2](https://s0.wp.com/latex.php?latex=E%28x_i%29+%3D+%5Bf%28x_i%29-l_i%5D%5E2&bg=ffffff&fg=000000&s=0&c=20201002)
where 
How would one visualize it? Let us analyze it.
Is it continuous? The pattern of this function looks something like,

which clearly indicates that it is discontinuous in nature. This creates a deeper set of problems – we cannot differentiate and hence certainly cannot use gradient descent (which is usually the best intended method). Thus, it is essential that we utilize a function which is continuous first.
Analyzing Eq. (A), suppose we have some 


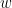
To combat this, we replace this with a sigmoid ‘


What is this activation function doing exactly?
It is taking in an ‘
This introduces non-linearity to the neural network and allows it to be more effective. You can prove that without introducing non-linearity at each layer, you would essentially just have a series of linear transformations which would cumulatively be as effective as a single linear transformation. This makes the neural network behave more as a linear regression model, defeating the entire purpose of achieving better and more accurate productivity.
This mapping naturally correlates to the concept of probabilities since their occurrence is always in the range (0, 1). Regardless of whatever ‘
If the probability is in high, it will belong to ‘Class 1.’ If the probability is in low, it will belong to ‘Class 0.’
This still does not solve our problem, as we do not know how to write the Error function for this set-up. To compute this error, we need to incorporate a classic probability notion: the probability of a coin flip resulting in heads or tails.
This scenario only interests us when the coin is biased. Assuming that this coin is
if 
else:




This can be translated to a function as:

where 

To maximize this probability, we apply logarithm to the coin ‘
Slowly but steadily, our problem is taking on the shape of Logistic Regression.
Our system takes 
Let


Relationship between  and P(
and P( ):
):
In linear regression, the model output 

where
The sigmoid function that we defined earlier is used to map
where
The sigmoid function squashes the values of z in the range ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D&bg=ffffff&fg=000000&s=0&c=20201002)




Entropy:
In Physics, entropy quantifies the chaos or disorder in a system. System with a higher level of chaos will have more entropy than a more ordered system.
With respect to information theory, entropy represents the amount of information obtained from a set of samples. Samples with more information will have less values for entropy and samples with less information will have higher values for it.
For example, a person wishes to choose between two different cars and the salesman tells him that both of them are good. Here the entropy will be high as the salesman’s answer is uncertain. It does not help the person in making his choice.
Note: A low value of entropy means that a clear decision was made but it is not necessary that the decision made is correct.
Building a final Error Function:
The total probability function for our system should ideally follow the following conditions:
- For input samples labeled with
,
- For input samples labeled with
,
Earlier, we had defined the system probability of a binary output as


The system probability should be high to ensure that the entropy is minimized with correct classes predicted for the input samples.
The error function is formulated as the negative log-likelihood of the above
We need to maximize the likelihood or log likelihood. This can also be done by minimizing the negative of the log likelihood, hence the negative of the log is taken.

Minimizing the Error Function using Gradient Descent:
Similar to linear regression, to find the local minima, the derivative of the error function with respect to the parameter
Applying Gradient Descent to update the parameter
where 

The error function defined is convex so it only has a global minima and not a local one.
Suppose that we have trained a logistic regression model for a problem with multiple parameters. Can we understand the impact of any single attribute parameter on the overall model output?
This implies that we require an interpretation of the parameters. In neural networks, this interpretation is lost but it can be carried out for linear systems.
Assume that we are developing a model which classifies people as good or bad athletes. It takes the person’s mass and height as input. Further, suppose that after training this system, it is seen that the parameter mass was assigned a weight of 0.2 and height was assigned a weight of 20. It is evidently clear that height has a greater effect on the model output as compared to the mass.
Similarly for a multi-dimensional classifier, the attributes which are assigned greater values for weights can be considered more important.
Adding a bias term allows us to make the model more robust. Without bias, all the trained models will output zero when the input is zero. In practical applications, not all the data is centered around zero. An example based on regression is predicting the price of a house with the attribute being the number of rooms. A house with zero rooms would definitely not have zero price. The bias term allows us to translate the model away from the origin.

Perceptron:
A neuron is an information processing unit, while a perceptron is an artificial neuron. It learns by adjusting the weights to learn a given target function 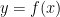
- A set of synapses or connecting links characterized by weight
- An adder summing the input signals weighted by synapses
- A linear combiner
- An activation function also known as the earlier touched upon squashing function. Examples include the step and sigmoid function

The process outlined below is called the forward pass. Rather than going into specifics, we will only analyze what the perceptron is doing. A single neuron is shown having inputs represented by 
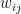

Here, the linear combination of the inputs is defined as 



Note that since we are taking into consideration 

Neural Networks:
The need for a neural network is emphasized below.

What should be multiplied by 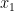
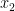
For example, a person draws a linear system as represented at 






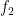

If both functions output ‘1,’ then we can classify the answer as ‘1.’ But if one or both of the outputs is ‘-1,’ then there is a problem at hand. To combat this, we can design one linear classifier for input dimensions 
Another way to look at this problem is by considering this example: You have 10 friends of whom all are getting the same information but giving different outputs in regards to whether you should buy a car. One friend may say ‘go ahead,’ some may say ‘not to even think about it’ and et all. One constant element is that the information always comes back to you. Modelling the above neuron problem, your friends become those weighted neurons while you are the final output neuron being influenced by their output.
The need for a neural network becomes justified for such cases where the problem cannot be solved in a linear way. Complex systems are hardly solved linearly. To maintain this ‘linear’ simplicity, we design the neural network in such a way that the output neuron is still linear and all the other neurons are semi-linear.

OR, AND and XOR Functions:
The OR function can be represented as:


Can a neural network classify this? If yes, then how? What will be the linear classifier here?
To answer these questions, we will have to specify a value that represents how much importance should be given to it. Point to ponder: What should be multiplied by 


Upon looking at the energy space provided on the right, it is clear that weights need to be specified so that a bias other than ‘0’ is obtained, which is done using a threshold.
The AND function can be represented as:


We only have to adjust the weights to classify this – putting ‘-1.5’ with ‘1,’ ‘1’ with 


Bias is significant in helping us define where our line passes through other than the origin. In reality, this is just a translation of the origin.
The XOR function can be represented as:


What would be the weights of this problem? Is a linearly separable solution even possible?
Turns out it is not. If one stretches a line in any possible manner to classify each point of the classes, there will always be some point that is wrongly classified in the boundary fold.
The problem can be addressed by the following nested relation:





The weights are adjusted and combined together. This is called feed forward as the model is feeding the values forward. Combinations of linear functions have been set up in a certain order so that non-linear problems can just as relevantly be solved. The intended function was linear but we were forced to insert non-linear operations – also known as activation functions – into it. The whole neural network collapses to just one neuron if the activation function happens to be linear, defeating the entire purpose of solving non-linear problems.
Hidden Layers in a Neural Network:
Increasing the number of layers introduces hidden layers in a neural network, as shown:

Applying the logic of having 1 classifier due to 1 neuron, we can achieve a more powerful model by increasing the number of hidden layers.

Suppose I have these 5 inputs represented by 




Here,

Resulting 



Take-Home Assignment:
Given the above example, assume that the activation function
Prove the same notion for a neural network with 2 hidden layers as shown in the figure below.


To maximize this probability, we apply logarithm to the coin ‘x_i‘ to get,
\; \; \; \; l_i\log p=(1-l_i) log (1-p)
How ?
LikeLike
Gradient methods generally work better optimizing log*P(x) than P(x) because the gradient of log*P(x) is generally more well-scaled. That is, it has a size that consistently and helpfully reflects the objective function’s geometry, making it easier to select an appropriate step size and get to the optimum in fewer steps. As we are interested in the probability of the coin, taking the log is more efficient in the mentioned set-up.
LikeLike